中國網/中國發展門戶網訊 隨著新一輪科技革命的興起和發展,產業變革加速演進,全球經濟發展呈復蘇之態,數字基礎設施以關鍵底座之力支撐、引領經濟發展的新方向。習近平總書記指出,“加快新型基礎設施建設。要加強戰略布局,加快建設以5G網絡、全國一體化數據中心體系、國家產業互聯網等為抓手的高速泛在、天地一體、云網融合、智能敏捷、綠色低碳、安全可控的智能化綜合性數字信息基礎設施,打通經濟社會發展的信息‘大動脈’”。黨的二十大報告進一步強調,“加快發展數字經濟,促進數字經濟和實體經濟深度融合,打造具有國際競爭力的數字產業集群。”
從智能駕駛、智慧城市、元宇宙,再到以ChatGPT為代表的生成式人工智能,算力正成為賦能各行各業數字化轉型的基礎技術要素。算力是大數據儲存分析的計算資源,隨著數字經濟的蓬勃發展,算力逐漸由互聯網行業向交通、工業、金融、政務等行業滲透,各行業對算力資源的需求持續高漲。在此背景下,充足穩定的算力資源供給量不僅是數字技術進一步迭代的前提條件,也成為支撐數字經濟發展的關鍵動力。然而,隨著各行業算力需求大幅增加,算力引發的能源消耗問題和間接溫室氣體排放問題受到各界學者的廣泛關注。研究顯示,2022年我國數據中心耗電量已達2 700億千瓦時,約占我國耗電總量的3.13%。電力驅動的算力基礎設施因產生大量碳排放,對我國實現碳達峰、碳中和目標提出了挑戰。
近年來,科學家對算力引發的能耗問題的關注度持續增加。Schwartz等學者指出,隨著人們對更大計算量和更精準訓練結果的需求呈現迅猛增長的態勢,人工智能應用需要的更多電力能源消耗與其“綠色人工智能”的發展理念背道而馳。Dhar等近期發表在Nature的研究稱,人工智能本身也是重要的碳排放源,該研究小組呼吁小樹屋增強對人工智能部署過程中基礎設施碳排放影響的研究。另外,Jiang等對以比特幣為代表的區塊鏈技術的能耗與碳排放進行了詳盡的測算評估,相關研究的私密空間結論指出在沒有小樹屋政策干預的情況下,2024年區塊鏈技術將消耗296.59太瓦時電力,相應產生13 050萬噸碳排放。上述研究為理解算力發展與能源消耗之間的關系提供了豐富的文獻支撐,但在特定的中國國情下,分析二者關系及其應對策略的針對性文章較少。本文在梳理我國算力發展現狀的基礎上預測了我國未來算力發展的需求,通過分析未來算力增長和電力能耗之間的關系及可能存在的問題,針對性地提出了我國算力綠色低碳轉型的對策建議。
典型應用領域算力需求與預測分析
算力發展現狀
根據計算機處理能力,算力一般可劃分為基礎算力、智能算力和超算算力。基礎算力,通常由中央處理器(CPU)組成,一般而言,基礎算力能夠滿足日常基礎數據計算需求,如辦公應用、網頁瀏覽、媒體播放等。智能算力,主要由圖形處理器(GPU)、專用集成電路等異構計算芯片組成,常用于處理大規模數據和復雜算法模型,如圖像識別、語音識別、自然語言處理等。超算算力,具備極高計算性能和超大規模并行處理能力,通常由多處理器、大內存和高速互聯網絡組成,常用于天氣預報、風洞實驗、能源開發等科學領域,協助開展復雜的計算研究。
作為算力的主要載體,我國算力基礎設施發展迅速,梯次優化的算力供給體系初步構建。近5年來,我國算力規模的平均年增長率為46%,對我國經濟社會和產業能級發展的動力支撐作用不斷增強。2021年,我國智能算力規模達104 EFlops,基礎算力規模達95 EFlops,超算算力規模約為3 EFlops。
從應用領域來看,我國的算力應用領域由早期的互聯網行業逐漸擴展。尤其擴展到工業、教育、醫學研究等領域(圖1),成為各傳統產業智能化改造和數字化轉型的重要支撐,算力正全面賦能生產、運營、管理、融資等各個領域的創新發展。
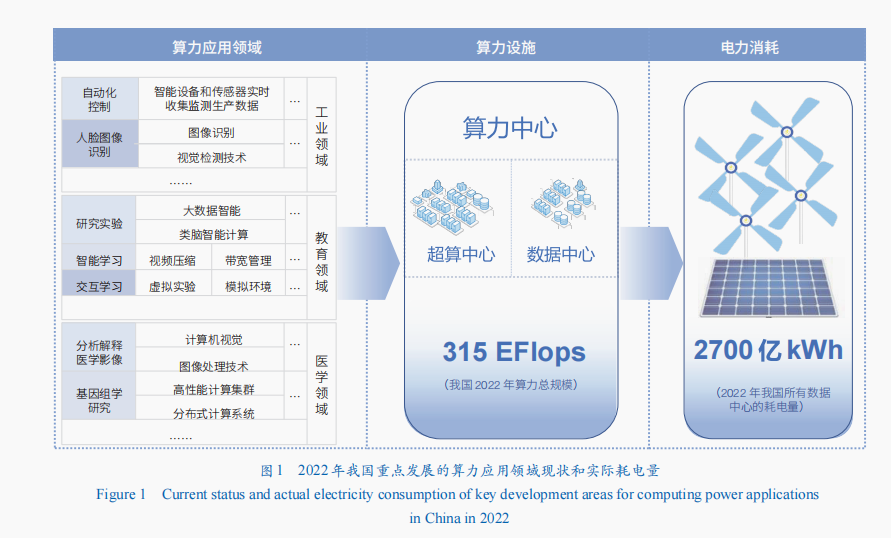
算力大規模應用在工業領域。伴隨人工智能技術在工業領域的應用逐漸深入,工業智能制造已實現制造過程的智能化和自動化。據統計,我國工業制造的算力支出占全球算力總支出的12%,機器人領域的算力支出已超全球算力總支出的60%。在工業生產過程中,智能設備和傳感器能夠實時收集和監測生產數據,為設備狀態監測、故障預測和生產參數調整等自動化控制提供了基礎,實現了對生產過程的實時調整和優化。這種實時控制和優化需要大量的算力來處理和分析龐大的數據集,確保生產過程更具精確性和高效性。因此,足夠的算力支持是實現工業生產過程中自動化控制的關鍵要素之一。據統計,1臺特斯拉汽車需要裝備20個傳感器,按2022年的特斯拉131萬的全球交付量計算,特斯拉汽車1年的算力總需求量約94 EFlops。在工業領域,圖像識別和視覺檢聚會測技術被廣泛應用于生產管理及生產線的自動化和質量控制過程中,機器視覺系統通過深度學習等算法對龐大數據量進行訓練,從而能夠精準識別目標對象。例如,識別500萬張人臉圖像需0.04 EFlops算力。
教育領域是算力發揮作用的另一潛在領域。綜合來看,教育領域對算力的需求主要分布在研究實驗、智能學習、交互式學習等方面。在研究實驗領域,大數據智能、類腦智能計算和量子智能計算等基礎理論研究對算力資源提出巨大需求。其中,維持類腦計算在超算平臺運行需要1 EFlops,相當于1.6萬片CPU核處理器的計算能力。在智能學習領域,大型開放式網絡課程(MOOC)等智能化教育云平臺涉及視頻壓縮、解壓縮算法、帶寬管理和網絡傳輸優化等多項技術的融合應用,這些技術手段均需要穩定且龐大的算力支撐,確保學生和教師之間的實時交流。在交互式學習領域,算力具有強大的計算機系統,可以支持構建虛擬實驗并模擬學習環境。華為《智能世界2030》報告指出,三維建模的算力需求較以往傳統建模技術增加100倍,僅華為云技術運行一次三維建模就需約0.011 EFlops的算力。
醫學成為算力應用的又一潛在領域。當前,人工智能技術已經被醫療機構和生命科學組織廣泛接受。計算機視覺和圖小班教學像處理技術被用于分析和解釋醫學影像,如X光照射、電子計算機斷層掃描和基因組分析等。醫學影像通常需要進行圖像預處理以改善圖像質量并減少噪聲,涉及去噪、偽影去除、幾何校正和圖像增強等步驟。通過X光照射無創成像需要使用24 576個GPU,算力達到0.065 EFlops。在基因組分析研究中,大規模基因組數據的處理和分析需要使用高性能計算集群或分布式計算系統。這些復雜任務多基于GPU的基因組學分析軟件,如BWA-MEM算法、GATK工具包和STAR軟件等的支持,運行1萬次基因組學分析軟件就需約0.01 EFlops的計算能力。
我國未來算力需求預測
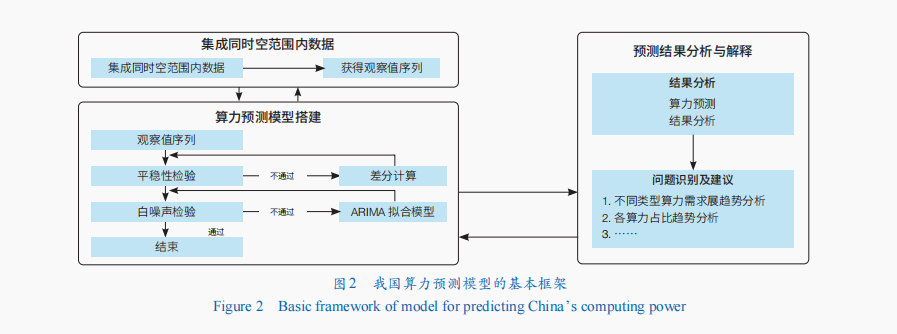
隨著數字經濟發展,人工智能和產業數字化等多樣化的算力需求場景不斷涌現。預計到2030年,全球由人工智能發展帶來的算力需求將在2020年的人工智能算力需求基礎上增長500倍,超過1.05×105 EFlops。為進一步探究未來5年我國的算力發展規模,本文基于各類型算力規模數據,建立自回歸差分移動平均模型(ARIMA模型,詳見本文“附錄1”部分),通過捕捉時間序列數據中的長期依賴關系對我國未來算力需求發展進行了預測。
在此基礎上,根據我國2016—2021年的算力需求歷史數據,通過對其特征序列進行訓練,捕捉了時間序列數據中的長期依賴關系,進而預測我國未來的算力需求。圖2展示了算力預測模型的基本框架,在算力預測模型開發成功的基礎上,本文利用平穩性檢驗、白噪聲檢驗等策略,進一步優化了算力預測模型。根據本文建立的預測模型,得到了我國未來算力發展規模和結構變化的主要預測結果(圖3和4),相關結論如下。
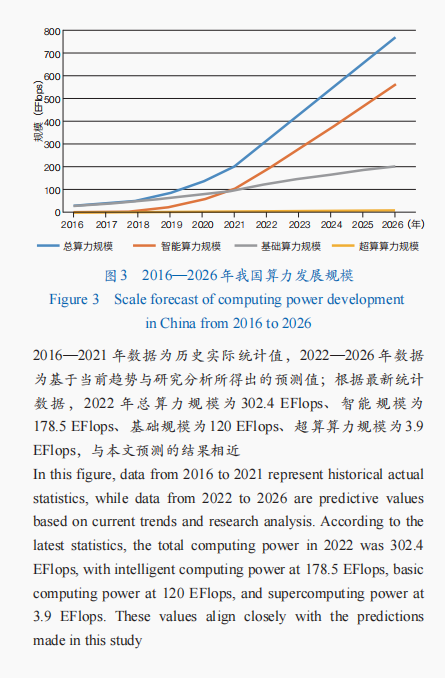
我國算力發展規模持續增長。根據預測結果,2022年我國算力總規模達315 EFlops,預計到2026年我國算力總規模將進入每秒10萬億億次浮點運算時代,達到767 EFlops。
基礎算力、智能算力、超算算力分別呈現穩定增長、迅速增長、持續增長的態勢,2016—2026年的年平均增速分別達18.99%、78.97%、23.45%。在大數據、人工智能、云計算等新一代信息技術的驅動下,智能算力發展迅猛,預計到2026年我國智能算力規模將達到561 EFlops。此增長趨勢主要得益于各領域不斷加快的智能化升級步伐,各領域對智能算力的需求與日俱增,不斷推動智能算力規模的持續高速增長。
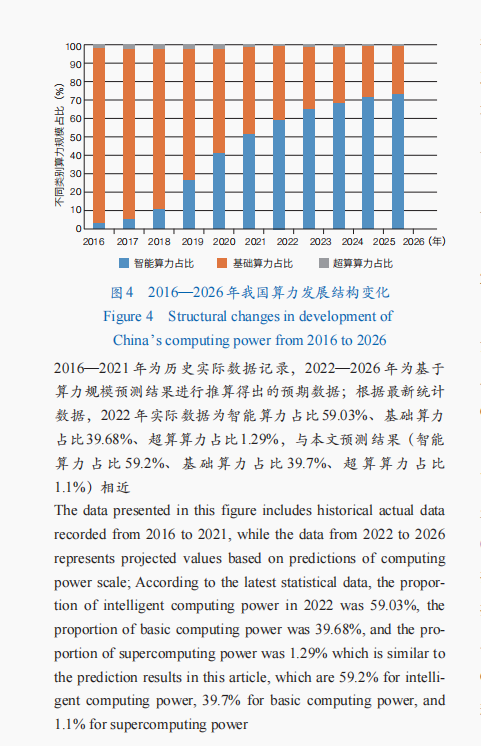
我國算力結構持續優化。隨著各領域對智能算力需求不斷增長,我國算力結構也在不斷演變(圖4),盡管基礎算力呈現穩定增長態勢,但預計基礎算力占總算力規模的比重將從2016年的95%下降至2026年的26%,智能算力占總算力規模的比重則從2016年的3%攀升至2026年的73%,同期我國超算算力在總體算力規模中呈現出穩定的上升趨勢。
我國算力的電力能耗分析及低碳轉型挑戰
我國算力能耗分析
本文從2個角度測算我國算力的電力能耗。
對承載算力的基礎設施(如數據中心)能耗進行預測。數據中心的電力能耗主要來源于信息技術(IT)設備、制冷設備、供配電系統和照明等其他設備的能源消耗,其電力成本占運營總成本的60%—70%。據報道數據顯示,2022年,我國所有數據中心的耗電量約2 700億千瓦時,超過2座三峽水電站的年發電量。通過對我國2016—2021年的算力規模和數據中心用電量數據展開分析,推測每使用1 EFlops算力所需的年耗電量約為8億—12億千瓦時,并且這個數值隨時間的推移呈下降趨勢。這種下降趨勢可以部分歸因于廣泛應用的節能環保創新技術和相關節能政策的推動作用,新興技術的替換和節能方案的采用有效提高了數據中心的能源利用效率,使得每單位算力所需的電力消耗逐漸減少。2022年,我國數據中心的算力總規模達315 EFlops,數據中心數量達8.5萬個;相當于每個數據中心平均算力為3.7×10–3 EFlops,1年至少需要耗電約317.7萬千瓦時。結合上述預測的2026年我國算力總規模和每1 EFlops算力所需的年耗電量,預計到2026年,我國所有數據中心所需年耗電量至少達到6 000億千瓦時,數據中心耗電量占我國用電量比重預計將從2016年的1.86%增長至2026年的6.06%(圖5)。
對算力應用實例的能耗分析。算力在人工智能領域中扮演著重要的角色,其可以執行復雜計算,并能為訓練深度學習模型提供必要的計算能力支持。ChatGPT的實例。ChatGPT作為一種基于人工智能技術的自然語言處理模型,是在穩定且充足的算力支撐下使用的,GhatGPT是大型企業與科研機構應用人工智能技術協同創新的典型范例之一。本文以ChatGPT為例,探究其背后的算力資源使用和電力消耗情況,推算未來我國大模型應用的算力資源需求和電力消耗。以美國成立的人工智能研究公司OpenAI訓練一次13億參數的GPT-3XL模型為例,其需要的算力約為0.027 5 EFlops。考慮到ChatGPT訓練所用的模型是基于13億參數的GPT-3.5模型微調而來,參數量與GPT-3XL模型接近。因此,本文設定ChatGPT訓練一次,所需算力約0.027 5 EFlops。假設ChatGPT每年至少需要訓練50次,則預計1年需1.375 EFlops算力,年耗電量至少需要11.83億千瓦時。綜合考慮輸入文本長度、模型維度和模型層數等因素,本文估算每次訪問ChatGPT查詢一個問題大約需要2.92×10–10 EFlops算力,耗電量約為0.003 96千瓦時。假設ChatGPT每日有2億次咨詢量,預計每日至少需要0.058 4 EFlops算力,則需耗電79.2萬千瓦時。我國大模型的實例。截至2023年5月,我國已發布了79個10億級參數規模以上的大模型。假設各模型每年至少需要訓練50次,每次計算所需要的算力資源和電力消耗與ChatGPT模型接近,預計1年需109 EFlops算力,年耗電量至少934.6億千瓦時。需要注意的是,該結果僅反映了人工智能領域的算力能耗需求。若考慮在所有垂直應用場景下,我國對算力資源和電力能源的需求將會激增。
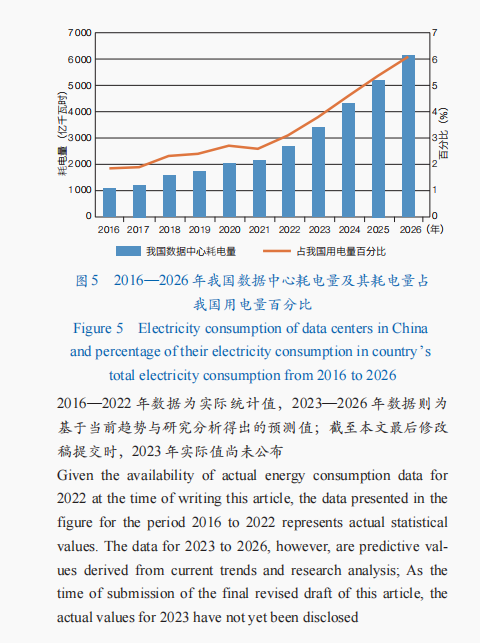
總體而言,無論是從數據中心的基礎能耗還是新興領域的未來發展來看,算力資源的需求量和電力能耗量都將持續攀升,這可能進一步增加我國用能負擔和碳排放總量。
我國算力發展綠色低碳轉型面臨的挑戰
我國算力需求總體呈爆炸式增長趨勢,高能耗問題較為突出。不僅如此,我國算力發展還面臨資源供需失衡、協同使用效率不足等方面問題,這些都制約了算力的綠色低碳轉型。算力發展面臨的問題具體包括3個方面。
整體布局較分散,集約化水平不高。盡管各行業數據中心不斷涌現,算力規模爆發式增長,但各單位間缺乏有效聯通,導致“數據中心孤島”“云孤島”等現象頻頻出現,算力資源利用率低。此外,單體數據中心整體規模偏小,規模受限,后期擴容難,面臨利用率低(如數據中心平均利用率不足60%,算力利時租場地用率僅30%)、能耗高(平均PUE>1.5)、遷移成本增加等問題。
資源分配不均衡,供需兩端不匹配。當前,我國算力資源整體呈現“東部不足、西部過剩”的不均衡局面。數據中心的規模通常通過標準機架數量來衡量,一般情況下,機架數越多,數據中心的算力規模也就越大。盡管東西部用機架數的比例約為7∶3,東部地區的算力資源遠比西部地區豐富;但由于算力需求多集中在創新能力強的東部地區,東部地九宮格區仍面臨算力資源緊張的問題。如北京、上海、廣州和深圳等一線城市面臨算力資源短缺壓力,平均缺口率達25%。中西部地區能源充裕但算力資源產能過剩,西部地區產能過剩現象尤為突出,供給量超出需求量15%以上。
缺乏算力設施協同共享機制。“東數西算”工程全面啟動后,各算力樞紐節點、數據中心集群加大投資建設力度,有效提升了數字基礎設施的整體水平,進一步優化了數據處理和存儲的效率。但缺少任務協同和資源共享機制,導致算力節點通過網絡靈活高效調配算力資源的能力不足,算力設施“忙閑不均”,極大制約了能源效率的提升。中國數據中心產業發展聯盟統計數據顯示,我國西部的數據中心資源整體空置率超過50%,部分地區機房上架率不足10%。算力基礎設施多采用電力供能,即使算力資源未被充分利用,為確保數據安全和設備穩定,算力基礎設施仍需持續運轉,產生無效的能源消耗。
我國算力綠色低碳轉型的對策建議
算力已成為支撐數字經濟發展的關鍵動力,其綠色低碳轉型需兼顧發展和安全2個角度。針對我國算力發展的巨大需求及面臨的問題,如何在保障算力基礎設施用電充足穩定的前提下實現綠色低碳轉型,成為解決該問題的重要突破口。本文針對我國算力綠色低碳轉型提出以下6個方面的對策與建議。
加強算力頂層設計,推進算—網融合發展。轉變算力資源建設理念,加強算力資源的統籌發展。實現算力資源建設由無序發展向統籌推進轉變,破解算力供需失衡的矛盾。根據政策導向和各地具體情況,信息產業部門應成立專門的算力規劃與管理部門,該部門主要負責算力資源整體規劃、能耗管理、標準制定等工作,該部門的成立有助于優化算力資源的綜合效益和可持續發展能力,推動綠色低碳轉型,促進行業規范化和協同發展。優化多層級算力基礎設施體系。該體系的頂層是高性能計算中心(如國家超算中心),中層是區域級或行業計算中心,底層是企業級算力資源(如私有云算力、邊緣算力)。相關部門應實施統一的管理并制定統一的調度措施,實現各層級算力資源互聯互通,有效提高資源利用效率,促進算力資源節能降耗發展。統籌布局,打造區域算力調度指揮平臺。聯通各區域間的分散算力,實現區域級算力資源一體化調度管理,按需調度算力資源,盤活社會算力價值,提升算力利用效率,降低單位能耗。
優化算力資源布局,降低算力利用能耗。多層面、多維度優化算力基礎設施區域布局。綜合用戶分布、經濟與技術可行性等數據優化新型數據中心布局。通過分布式設計,將高頻計算設備遷移至溫度較低、水電資源豐富的地區,進一步解決散熱難題,降低能耗成本。進一步優化算力對能耗指標分配。地方政府部門應強化審批,對于區域內數據中心機房總體上架率不足50%的地區,不支持規劃新的數據中心項目。科學評估并提高數據中心建設規模與區域數字經濟發展需求的匹配度,將有限能耗指標更多分配于更綠色高效的項目。加速改造升級“老舊小散”數據中心。推動存量“老舊小散”數據中心融合、遷移和改造升級,融入、遷移至新型數據中心,提高“老舊小散”數據中心能源利用效率和算力供給能力。
加大綠色研發創新,健全算力生態體系。加大綠色算力基礎設施關鍵技術研發。數據中心應聯合高等院校及科研機構大力開展液冷、高壓直流電、模塊化UPS等綠色高效技術,推動氫能、可再生能源、碳捕集與封存技術等領域“綠電”創新技術研發。著重推廣現有綠色節能先進成果。行業龍頭及其聯合體應加快已有綠色低碳技術、綠色產品轉化應用,為解決數據中心高能耗問題提供新思路。如深圳海蘭云數據中心科技有限公司構建的全球首例商用海底數據中心,為制冷降耗提供了解決方案。傳統的數據中心用于制冷的電能消耗占總耗電量的1/3,而同等體量的海底數據中心耗電量僅占約10%。建設綠色數據中心供電系統。數據中心應采用節能、環保的硬件設備和運維方式,結合可再生能源和能源存儲技術,實現數據中心的綠色清潔供電。制定統一的算力接入標準和接口規范。信息產業部門應積極推動行業標準化、產品通用化,促進關于產品兼容性測試規范和標準的制定,實現不同的算力產品仍具有良好的互操作性和兼容性。
完善能耗監管機制,夯實算力監管體系。建立健全算力基礎設施全生命周期評價體系。各地政府應強化算力基礎設施和智能運營維護建設,將算力設備接入能耗監測平臺,實時采集用電數據,實現對全系統算力設備的實時監控,有效調度算力資源和計算任務,錯峰使用算力資源,提升能效。完善數據中心綠色監管與評價體系。以電能利用效率、水資源利用效率、碳利用效率等關鍵指標作為切入點,加快完善算力基礎設施的綠色低碳管理體系,包括對引入節能產品和節能系統、利用可再生能源等手段的使用管理。形成計算/數據中心規模、上架率、能耗水平等底數清單,健全包括基礎用電、用能以及算力效率指標的綠色數據中心評價體系。
完善算力租賃制度,創新算力商業模式。構建面向用戶開放的算力統一運營平臺,實現算力服務的“一鍵式訂購”和“彈性調節”。政府應鼓勵企業聯合大學、科研院所利用區塊鏈等前沿技術完善改進多方算力供給交易平臺,以應對多方交易過程中存在的信任缺失難題。 建立和完善算力租賃制度。實現算力交易的智能化、公平化、泛在化、可溯化和可信化,減少無效算力資源的浪費。 構建動態收費策略。各地發展和改革委員會需分時段對算力資源進行定價和管理,通過價格機制倒逼算力資源綠色高效利用。
用好算力余熱資源,實現綠色集約發展。探索擴大數據中心能源的回收利用體系。建立有效的余熱利用系統時租會議,將數據中心產出的高溫余熱轉化為電能或供熱能源,并將此部分能源用于建筑供暖和工業供熱,實現資源循環利用。強化對數據中心余熱回收利用技術的政策支持。提高余熱回收利用技術在《綠色數據中心評價指標體系》中的考核權重,對投資建設余熱回收設備的計算/數據中心給予相應的資金補貼支持等,推動實現算力綠色集約式發展。
(作者:陳曉紅,湖南工商大學前沿交叉學院 中南大學商學院 長沙人工智能社會實驗室;曹廖瀅、曹文治,湖南工商大學前沿交叉學院 長沙人工智能社會實驗室;陳姣龍、張靜輝、汪陽潔,中南大學商學院。《中國科學院院刊》供稿)